大家都说yarn比npm好,今天全局安装yarn尝试下
cnpm install -g yarn
安装完成后,查看yarn版本
yarn --version
项目搭建
安装vuepress
yarn global add vuepress
初始化项目
创建项目目录blog
mkdir blog
cd blog
初始化
yarn init -y
初始化完成后,会创建一个package.json。在package.json中,配置启动命令
{ "name": "blog","version": "1.0.0": { "docs:dev": "vuepress dev docs" } }
创建docs目录,主要用于放置我们写的.md类型的文章以及.vuepress相关的配置
mkdir docs
cd docs
mkdir .vuepress
页面具体内容配置
新建一个总的配置文件config.js,这个文件的名字是固定的.
cd .vuepress
touch config.js
我用windows,没有touch命令,直接手动创建了……
module.exports = {
title: 'cyy的博客'分享,从前端到Node.js再到数据库'页面404页面,vuepress默认打开的是docs下的readme.md文件,由于你没有创建,所以找到的是vuepress默认提供的404页面,关于这有点,我们借助vue-devtools工具来查看一下vue的结构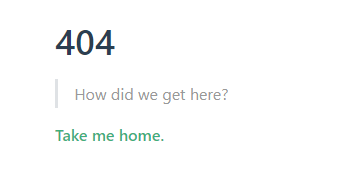
在docs目录下创建README.md文件,再运行,就可以看到运行起来的效果
vuepress使用markdown语法,不会的就先去菜鸟教程简单熟悉下:https://www.runoob.com/markdown/md-tutorial.html
设置封面页
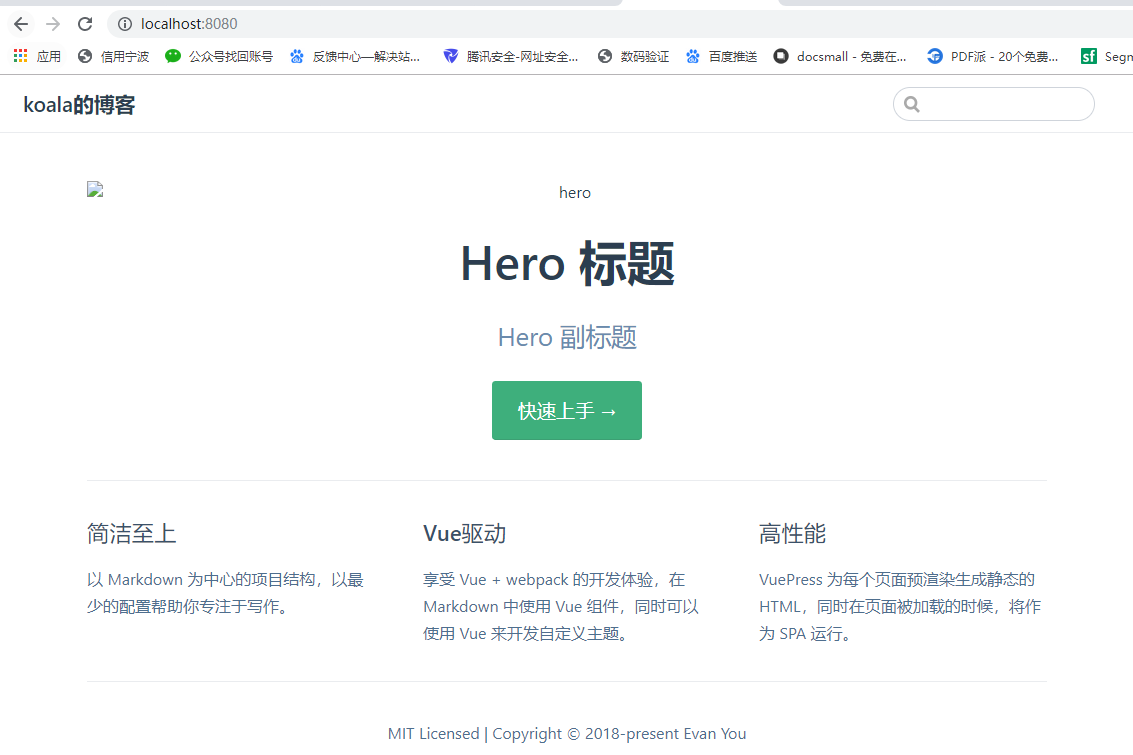
此时README文件中没有内容,封面页是空的,我们可以通过在这个markdown文件中写一些内容,同时官方也给我们提供了封面页的模板(个人觉得还是比较实用的):
--- home: true heroImage: /hero.png heroText: Hero 标题 tagline: Hero 副标题 actionText: 快速上手 → actionLink: /zh/guide/ features: - title: 简洁至上 details: 以 Markdown 为中心的项目结构,以最少的配置帮助你专注于写作。 - title: Vue驱动 details: 享受 Vue + webpack 的开发体验,在 Markdown 中使用 Vue 组件,同时可以使用 Vue 来开发自定义主题。 - title: 高性能 details: VuePress 为每个页面预渲染生成静态的 HTML,同时在页面被加载的时候,将作为 SPA 运行。 footer: MIT Licensed | Copyright © 2018-present Evan You ---
配置导航栏nav
在config.js中添加:
themeConfig:{ nav: [ {text: "主页",link: "/" },{ text: "node",link: "/node/" },{ text: "前端",link: "/webframe/"},{ text: "数据库",link: "/database/" },{ text: "android",link: "/android/" } ] }

如果想要展示二级导航,可以这样配置:
themeConfig:{ nav: [{text: "主页",{ text: "前端" } ],}
效果如图所示:

ctrl+c
cd blog
yarn docs:dev
当你使用上面的方式配置nav时,目录结构最好和我创建的一样 项目目录结构如下:
yarn install

配置侧边栏slider
1.自动获取侧边栏内容
如果你希望自动生成当前页面标题的侧边栏,可以在config.js中配置来启用
// .vuepress/config.js module.exports = { themeConfig:{ sidebar: 'auto' sidebarDepth: 1 } }
2.展示每个页面的侧边栏
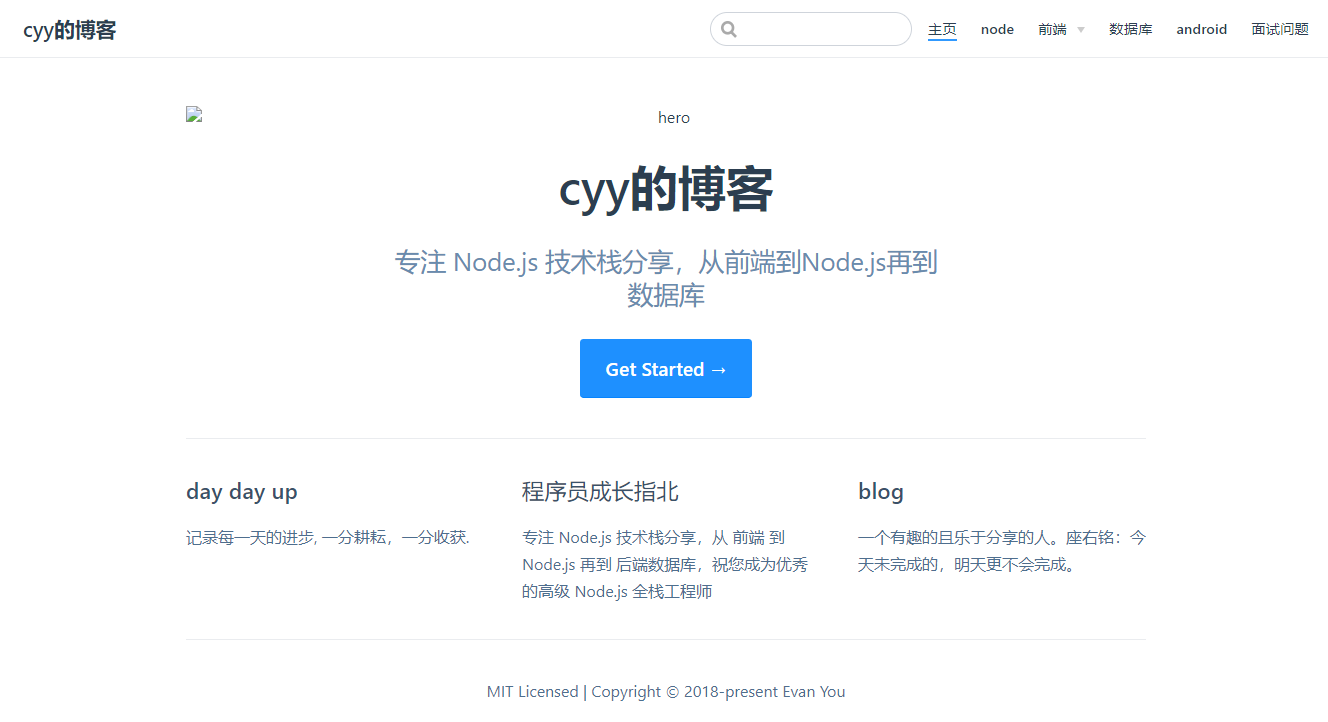
如果你希望为不同的页面组显示不同的侧边栏,就和官网一样,点击指南显示的是对应的侧边栏,目前目录有node \ database \ web等
module.exports = { themeConfig:{ sidebar:{ "/node/":[ ["","node目录"],["path","作为前端也需要知道的路径知识"] ],"/web/"false] ] } ] } } }
这里我在node目录下新建了一个index.md
## 前言 写完上一篇文章[想学Node.js,stream先有必要搞清楚](https:juejin.im/post/5d25ce36f265da1ba84ab97a) 留下了悬念,`stream`对象数据流转的具体内容是什么?本篇文章将为大家进行深入讲解。 ## Buffer探究 看一段之前使用`stream`操作文件的例子: ```JavaScript var fileName = path.resolve(__dirname,'data.txt'); var stream=fs.createReadStream(fileName); console.log('stream内容'function(chunk){ console.log(chunk instanceof Buffer) console.log(chunk); }) ``` 看一下打印结果,发现第一个stream是一个对象 ,截图部分内容。  第二个和第三个打印结果,  Buffer对象,类似数组,它的元素为16进制的两位数,即0到255的数值。可以看出stream中流动的数据是Buffer类型,二进制数据,接下来开始我们的Buffer探索之旅。 ## 什么是二进制 二进制是计算机最底层的数据格式,字符串,数字,视频,音频,程序,网络包等,在最底层都是用二进制来进行存储。这些高级格式和二进制之间,都可以通过固定的编码格式进行相互转换。 例如,C语言中int32类型的十进制整数(无符号),就占用32bit即4byte,十进制的3对应的二进制就是`00000000 00000000 00000000 00000011`。字符串也是同理,可以根据ASCII编码规则或者unicode编码规则(如utf-8)等和二进制进行相互转换。总之,计算机底层存储的数据都是二进制格式,各种高级类型都有对应的编码规则和二进制进行相互转换。 ## node中为什么会出现Buffer这个模块 在最初的`javascript`生态中,`javascript`还运行在浏览器端,对于处理Unicode编码的字符串数据很容易,但是对于处理二进制以及非`Unicode`编码的数据无能为力,但是对于`Server`端操作`TCP/HTTP`以及`文件I/O`的处理是必须的。我想就是因此在`Node.js`里面提供了`Buffer`类处理二进制的数据,可以处理各种类型的数据。 Buffer模块的一个说明。 > 在Node.js里面一些重要模块net、http、fs中的数据传输以及处理都有Buffer的身影,因为一些基础的核心模块都要依赖Buffer,所以在node启动的时候,就已经加载了Buffer,我们可以在全局下面直接使用Buffer,无需通过require()。且 Buffer 的大小在创建时确定,无法调整。 ## Buffer创建 在 `NodeJS v6.0.0`版本之前,`Buffer`实例是通过 Buffer 构造函数创建的,即使用 new 关键字创建,它根据提供的参数返回不同的 Buffer,但在之后的版本中这种声明方式就被废弃了,替代 new 的创建方式主要有以下几种。 #### 1. Buffer.alloc 和 Buffer.allocUnsafe(创建固定大小的buffer) 用 `Buffer.alloc` 和 `Buffer.allocUnsafe` 创建 Buffer 的传参方式相同,参数为创建 Buffer 的长度,数值类型。 ```JavaScript Buffer.alloc 和 Buffer.allocUnsafe 创建 Buffer // Buffer.alloc 创建 Buffer,创建一个大小为6字节的空buffer,经过了初始化 let buf1 = Buffer.alloc(6); Buffer.allocUnsafe 创建 Buffer,创建一个大小为6字节的buffer,未经过初始化 let buf2 = Buffer.allocUnsafe(6); console.log(buf1); <Buffer 00 00 00 00 00 00> console.log(buf2); <Buffer 00 e7 8f a0 00 00> ``` 通过代码可以看出,用 `Buffer.alloc` 和 `Buffer.allocUnsafe` 创建` Buffer` 是有区别的,`Buffer.alloc` 创建的 `Buffer` 是被初始化过的,即 `Buffer` 的每一项都用 00 填充,而 `Buffer.allocUnsafe` 创建的 Buffer 并没有经过初始化,在内存中只要有闲置的 Buffer 就直接 “抓过来” 使用。 `Buffer.allocUnsafe` 创建 `Buffer` 使得内存的分配非常快,但已分配的内存段可能包含潜在的敏感数据,有明显性能优势的同时又是不安全的,所以使用需格外 “小心”。 #### 2、Buffer.from(根据内容直接创建Buffer) > Buffer.from(str,) 支持三种传参方式: - 第一个参数为字符串,第二个参数为字符编码,如 `ASCII`、`UTF-8`、`Base64` 等等。 - 传入一个数组,数组的每一项会以十六进制存储为 `Buffer` 的每一项。 - 传入一个` Buffer`,会将 `Buffer` 的每一项作为新返回 `Buffer` 的每一项。 **说明:`Buffer`目前支持的编码格式** - ascii - 仅支持7位ASCII数据。 - utf8 - 多字节编码的Unicode字符 - utf16le - 2或4个字节,小端编码的Unicode字符 - base64 - Base64字符串编码 - binary - 二进制编码。 - hex - 将每个字节编码为两个十六进制字符。 ##### 传入字符串和字符编码: ```JavaScript 传入字符串和字符编码 let buf = Buffer.from("hello","utf8"); console.log(buf); <Buffer 68 65 6c 6c 6f> ``` ##### 传入数组: ```JavaScript 数组成员为十进制数 let buf = Buffer.from([1,2,3]); console.log(buf); <Buffer 01 02 03> ``` ```JavaScript 数组成员为十六进制数 let buf = Buffer.from([0xe4,0xbd,0xa0,0xe5,0xa5,0xbd <Buffer e4 bd a0 e5 a5 bd> console.log(buf.toString("utf8")); 你好 ``` 在 `NodeJS` 中不支持 `GB2312` 编码,默认支持 `UTF-8`,在 `GB2312` 中,一个汉字占两个字节,而在 `UTF-8` 中,`一个汉字`占三个字节,所以上面 “你好” 的 `Buffer` 为 6 个十六进制数组成。 ```JavaScript 数组成员为字符串类型的数字 let buf = Buffer.from(["1","2","3"]); console.log(buf); ``` 传入的数组成员可以是任何进制的数值,当成员为字符串的时候,如果值是数字会被自动识别成数值类型,如果值不是数字或成员为是其他非数值类型的数据,该成员会被初始化为 00。 创建的 `Buffer` 可以通过 `toString` 方法直接指定编码进行转换,默认编码为 `UTF-8`。 ##### 传入 Buffer: ```JavaScript 传入一个 Buffer let buf1 = Buffer.from("hello",1)">); let buf2 = Buffer.from(buf1); console.log(buf1); <Buffer 68 65 6c 6c 6f> console.log(buf2); <Buffer 68 65 6c 6c 6f> console.log(buf1 === buf2); false console.log(buf1[0] === buf2[0]); true buf1[1]=12; console.log(buf1); <Buffer 68 0c 6c 6c 6f> console.log(buf2); ``` 当传入的参数为一个 `Buffer` 的时候,会创建一个新的 `Buffer` 并复制上面的每一个成员。 `Buffer` 为引用类型,一个 `Buffer` 复制了另一个 Buffer 的成员,当其中一个 Buffer 复制的成员有更改,另一个 Buffer 对应的成员不会跟着改变,说明传入`buffer`创建新的`Buffer`的时候是一个深拷贝的过程。 ## Buffer的内存分配机制 **buffer对应于 V8 堆内存之外的一块原始内存** `Buffer`是一个典型的`javascript`与`C++`结合的模块,与性能有关的用C++来实现,`javascript` 负责衔接和提供接口。`Buffer`所占的内存不是`V8`堆内存,是独立于`V8`堆内存之外的内存,通过`C++`层面实现内存申请(可以说真正的内存是`C++`层面提供的)、`javascript` 分配内存(可以说`JavaScript`层面只是使用它)。`Buffer`在分配内存最终是使用`ArrayBuffer`对象作为载体。简单点而言, 就是`Buffer`模块使用`v8::ArrayBuffer`分配一片内存,通过`TypedArray`中的`v8::Uint8Array`来去写数据。 #### 内存分配的8K机制 - 分配小内存 说道Buffer的内存分配就不得不说`Buffer`的`8KB`的问题,对应`buffer.js`源码里面的处理如下: ```JavaScript Buffer.poolSize = 8 * 1024; allocate(size) { if(size <= 0 ) return FastBuffer(); if(size < Buffer.poolSize >>> 1if(size > poolSize - poolOffset) createPool(); var b = allocPool.slice(poolOffset,poolOffset + size); poolOffset += size; alignPool(); return b } else { createUnsafeBuffer(size); } } ``` 源码直接看来就是以8KB作为界限,如果写入的数据大于8KB一半的话直接则直接去分配内存,如果小于4KB的话则从当前分配池里面判断是否够空间放下当前存储的数据,如果不够则重新去申请8KB的内存空间,把数据存储到新申请的空间里面,如果足够写入则直接写入数据到内存空间里面,下图为其内存分配策略。  看内存分配策略图,如果当前存储了2KB的数据,后面要存储5KB大小数据的时候分配池判断所需内存空间大于4KB,则会去重新申请内存空间来存储5KB数据并且分配池的当前偏移指针也是指向新申请的内存空间,这时候就之前剩余的6KB(8KB-2KB)内存空间就会被搁置。至于为什么会用`8KB`作为`存储单元`分配,为什么大于`8KB`按照大内存分配策略,在下面`Buffer`内存分配机制优点有说明。 - 分配大内存 还是看上面那张内存分配图,如果需要超过`8KB`的`Buffer`对象,将会直接分配一个`SlowBuffer`对象作为基础单元,这个基础单元将会被这个大`Buffer`对象独占。 ```JavaScript Big buffer,just alloc one this.parent = new SlowBuffer(this.length); this.offset = 0; ``` 这里的`SlowBUffer`类实在`C++`中定义的,虽然引用buffer模块可以访问到它,但是不推荐直接操作它,而是用`Buffer`替代。这里内部`parent`属性指向的`SlowBuffer`对象来自`Node`自身`C++`中的定义,是`C++`层面的`Buffer`对象,所用内存不在`V8`的堆中 - 内存分配的限制 此外,`Buffer`单次的内存分配也有限制,而这个限制根据不同操作系统而不同,而这个限制可以看到`node_buffer.h`里面 ```C static const unsigned int kMaxLength = sizeof(int32_t) == sizeof(intptr_t) ? 0x3fffffff : 0x7fffffff; ``` 对于32位的操作系统单次可最大分配的内存为1G,对于64位或者更高的为2G。 #### buffer内存分配机制优点 `Buffer`真正的内存实在`Node`的`C++`层面提供的,`JavaScript`层面只是使用它。当进行小而频繁的`Buffer`操作时,采用的是`8KB`为一个单元的机制进行预先申请和事后分配,使得`Javascript`到操作系统之间不必有过多的内存申请方面的系统调用。对于大块的`Buffer`而言(大于`8KB`),则直接使用`C++`层面提供的内存,则无需细腻的分配操作。 ## Buffer与stream #### stream的流动为什么要使用二进制Buffer 根据最初代码的打印结果,`stream`中流动的数据就是`Buffer`类型,也就是`二进制`。 **原因一:** `node`官方使用二进制作为数据流动肯定是考虑过很多,比如在上一篇 [想学Node.js,stream先有必要搞清楚](https:juejin.im/post/5d25ce36f265da1ba84ab97a)文章已经说过,stream主要的设计目的——是为了优化`IO操作`(`文件IO`和`网络IO`),对应后端无论是`文件IO`还是`网络IO`,其中包含的数据格式都是未知的,有可能是字符串,音频,视频,网络包等等,即使就是字符串,它的编码格式也是未知的,可能`ASC编码`,也可能`utf-8`编码,对于这些未知的情况,还不如直接使用最通用的格式`二进制`. **原因二:** `Buffer`对于`http`请求也会带来性能提升。 举一个例子: ```JavaScript const http = require('http'); const fs = require('fs'); const path = require('path'); const server = http.createServer( (req,res) { const fileName = path.resolve(__dirname,'buffer-test.txt'); fs.readFile(fileName,1)"> (err,data) { res.end(data) 测试1 :直接返回二进制数据 res.end(data.toString()) // 测试2 :返回字符串数据 }); }); server.listen(8000); ``` 将代码中的`buffer-test`文件大小增加到`50KB`左右,然后使用`ab`工具测试一下性能,你会发现无论是从`吞吐量`(Requests per second)还是连接时间上,返回二进制格式比返回字符串格式效率提高很多。为何字符串格式效率低?—— 因为网络请求的数据本来就是二进制格式传输,虽然代码中写的是 `response` 返回字符串,最终还得再转换为二进制进行传输,多了一步操作,效率当然低了。 #### Buffer在stream数据流转充当的角色 我们可以把整个`流(stream)`和`Buffer`的配合过程看作`公交站`。在一些公交站,`公交车`在没有装满乘客前是不会发车的,或者在特定的时刻才会发车。当然,乘客也可能在不同的时间,人流量大小也会有所不同,有人多的时候,有人少的时候,`乘客`或`公交车站`都无法控制人流量。 不论何时,早到的乘客都必须等待,直到`公交车`接到指令可以发车。当乘客到站,发现`公交车`已经装满,或者已经开走,他就必须等待下一班车次。 总之,这里总会有一个等待的地方,这个`等待的区域`就是`Node.js`中的`Buffer`,`Node.js`不能控制数据什么时候传输过来,传输速度,就好像公交车站无法控制人流量一样。他只能决定什么时候发送数据(公交车发车)。如果时间还不到,那么`Node.js`就会把数据放入`Buffer`等待区域中,一个在RAM中的地址,直到把他们发送出去进行处理。 **注意点:** `Buffer`虽好也不要瞎用,`Buffer`与`String`两者都可以存储字符串类型的数据,但是,`String`与`Buffer`不同,在内存分配上面,`String`直接使用`v8堆存储`,不用经过`c++`堆外分配内存,并且`Google`也对`String`进行优化,在实际的拼接测速对比中,`String`比`Buffer`快。但是`Buffer`的出现是为了处理二进制以及其他非`Unicode`编码的数据,所以在处理`非utf8`数据的时候需要使用到`Buffer`来处理。
设置的效果图如下: 在node导航下:

自定义布局内容
网站的导航和侧边栏都已经配置好之后,如果你觉得页面不是很符合你的预期,你也可以自定修改成你想要的效果。比如就像我的博客中左侧固定的内容,就是自定义的全局组件. 这里使用vuepress提供的插件机制来实现
<template>
<div class="fixed_container">
<div class="tencent_code">
<h4>关注作者公众号</h4>
<p>和万千小伙伴一起学习</p>
</div>
<div class="group_code">
<h4>加入技术交流群</h4>
<p>扫描二维码 备注
<span> 加群</span>
</p>
</div>
</div>
</template>
<script>
export default {
name: 'fixed'
}
</script>
插件 plugins:[ { name:"page-plugin"文件夹下的.vue文件同名,全局UI就是一个Vue组件; 其实vuepress也提供了一些内置的全局UI组件,例如:back-to-top,popup,nprogress等.
配置插件
UI插件
配置内置的全局UI,首先需要插件:
yarn add -D @vuepress/plugin-back-to-top @vuepress/plugin-nprogress
在config.js中配置:
plugins:[ ["@vuepress/back-to-top"],1)"> 返回顶部 ["@vuepress/nprogress"],1)"> 加载进度条 ]
支持PWA
vuepress还有一个我比较看重的优势,就是支持PWA,当用户没有网的情况下,一样能继续的访问我们的网站
首先需要安装插件:
yarn add -D @vuepress/plugin-pwa
在config.js中配置:
module.exports = { plugins: ['@vuepress/pwa' }] }
为了让网站完全地兼容 PWA,你需要:
- 在 .vuepress/public 提供 Manifest 和 icons
- 在
.vuepress/config.js添加正确的head links
配置 module.exports = { head: [ ['link',{ rel: 'icon',href: `/favicon.ico` }],1)">增加manifest.json ['link',{ rel: 'manifest',href: '/manifest.json' }],],}
manifest.json 文件
(路径是docs/.vuepress/public/manifest.json)
{ "name": "koala_blog"博客" }
配置评论
valine 使用
然后创建应用,获取APP ID 和APP KEY

应用创建好以后,进入刚刚创建的应用,选择左下角的设置 > 应用Key,然后就能看到你的APP ID 和APP Key了
安装:
yarn add vuepress-plugin-comment -D
快速使用
在.vuepress下的config.js插件配置中:
module.exports = { plugins: [ [ 'vuepress-plugin-comment' options选项中的所有参数,会传给Valine的配置 options: { el: '#valine-vuepress-comment''Your own appKey' } } ] ] }
gitTalk 使用
主题样式修改
vuepress默认是主题颜色是绿色,如果你不喜欢可以对其进行更改. 如果要对默认设置的样式进行简单颜色替换,或者自定义一些颜色变量供以后使用,可以在.vuepress/styles下创建palette.styl文件.
你可以调整的颜色变量:
颜色 $textColor ?= #2c3e50 $accentColor ?= #1e90ff $grayTextColor ?= #666 $lightTextColor ?= #999 $borderColor ?= #eaecef $codeBgColor ?= #282c34 $arrowBgColor ?= #ccc $navbarColor ?= #fff $headerColor ?= #fff $headerTitleColor ?= #fff $nprogressColor ?= $accentColor 布局 bannerHeight ?= 12rem
响应式 breakpoints MQNarrow ?= 1024px MQMobileNarrow ?= 480px
如果要添加额外的样式,vuepress也是提供了简便方法的,只要在.vuepress/styles文件下创建一个 index.styl,在里面写css样式即可,注意文件命名是固定的.
改完以后是这个样纸滴
部署
Nginx部署
第一步: 确保你满足下面几个条件
第二步: 打包你的项目
运行npm run docs:build将项目打包,默认打包文件在docs/.vuepress/dist目录下

第三步: 配置Nginx
我一般都是宝塔安装lnmp环境
将静态资源文件放置到服务器上,路径为配置的/usr/web/inode/dist,可以借助xftp工具上传也可以通过git克隆,选择适合自己的方式就可以
可以通过域名来访问你的网站啦!!!
github部署
将代码部署到 Github Pages,你可以看vuepress文档: vuepress部署,也参照我这里写的的步骤来部署
第一步: 首先确保你的项目满足以下几个条件:
- 文档放置在docs目录中
- 使用的是默认的构建输出位置
- vuepress以本地依赖的形式被安装到你的项目中
第二步: 创建github仓库
在github上创建一个名为blog的仓库,并将代码提交到github上
module.exports = { base: "/blog/" }
第四步: 在项目根目录中,创建一个如下的脚本文件deploy.sh
#!/usr/bin/env sh # 确保脚本抛出遇到的错误 set -e # 生成静态文件 npm run docs:build # 进入生成的文件夹 cd docs/.vuepress/dist git init git add -A git commit -m 'deploy' # 如果发布到 https:<USERNAME>.github.io/<REPO> git push -f git@github.com:<USERNAME>/<REPO>.git master:gh-pages # 例如 git push -f git@github.com:koala-coding/blog.git master:gh-pages cd -
第五步: 双击 deploy.sh 运行脚本
会自动在我们的 GitHub 仓库中,创建一个名为 gh-pages 的分支,而我们要部署到 GitHub Pages 的正是这个分支
第六步: setting Github Pages 这是最后一步了,在 GitHub 项目点击 Setting 按钮,找到 GitHub Pages - Source,选择 gh-pages 分支,点击 Save 按钮后,静静地等待它部署完成即可。
