翻译自 Russ Cox
当我向新手程序员解释Go语言的时候,我发现通过对于操作代价的正确认识,常常能帮助我们理解Go语言内存中的值是个什么样子。本文就Go语言的基本类型,structs,arrays和slices加以讨论。
### 基本类型 先来几个简单的例子:

变量`i`属于类型`int`,在内存中用一个32位字长(word)表示。(所有图片展示的都是32位内存布局方式;在当前实现中,只有指针类型在64位机上变大了--int还是32位--但仍可以选择使用64位来代替32位。)
变量`j`由于做了精确的转换,属于`int32`类型。尽管i和j有着相同的内存布局,但是它们属于不同的类型:赋值操作 ```i = j```是一种类型错误,必须写成更精确的转换方式:```i = int(j)```。
变量`f`属于`float`类型,Go语言当前使用32位浮点型值表示(`float32`)。它与int32很像,但是内部实现不同。 ### 结构体(struct)和指针 接下来,变量```bytes```的类型是`[5]byte`,一个由5个字节组成的数组。它的内存表示就是连起来的5个字节,就像C的数组。相似地,变量```primes```是一个4位`int`型数组。
与C相同而与Java不同的是,Go语言让程序员决定何时使用指针。
举例来说,这种类型定义:
```type Point struct {X,Y int} ```
先来定义一个简单的struct类型,名为Point,表示内存中两个相邻的整数。
如下图,struct的属性在内存中是并排列出的。
`type Rect1 struct { Min,Max Point}`
`type Rect2 struct { Min,Max *Point}` 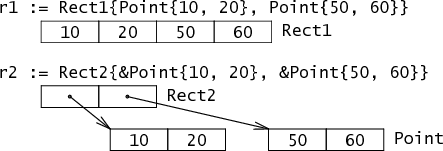
Rect1是一个具有两个Point类型属性的struct,由在一行的两个Point--四个int代表。Rect2是一个具有两个`*Point`类型属性的struct,由两个`*Point`表示。
使用过C的程序员可能对`Point`属性和`*Point`属性的不同毫不见怪,但用惯Java或Python的程序员们可能就不那么轻松了。Go语言给了程序员基本内存层面的控制,由此提供了诸多能力,如控制给定数据结构集合的总大小、内存分配的次数、内存访问模式以及建立优秀系统的所有要点。* ### 字符串 有了前面的准备,我们就可以开始研究更有趣的数据类型了。

(灰色的箭头表示已经实现的但不能直接可见的指针)
字符串在Go语言内存模型中用一个2字长的数据结构表示。它包含一个指向字符串存储数据的指针和一个长度数据。因为`string`类型是不可变的,对于多字符串共享同一个存储数据是安全的。切分(slice)s会得到一个新的2字长结构,一个可能不同的但仍指向同一个字节序列(即上文说的存储数据)的指针和长度数据。这意味着字符串切分可以在不涉及内存分配或复制操作。这使得字符串切分的效率等同于传递下标。
(说句题外话,在Java和其他语言里有一个[有名的“疑难杂症”](http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=4513622):在你分割字符串并保存时,对于源字符串的引用在内存中仍然保存着完整的原始字符串--即使只有一小部分仍被需要。Go也有这个“毛病”。另一方面,我们努力但[又失败了的](https://code.google.com/p/go/source/detail?r=70fa38e5a5bb)是,让字符串分割操作变得昂贵--包含一次分配和一次复制。在大多数程序中都避免了这么做。) ### Slices 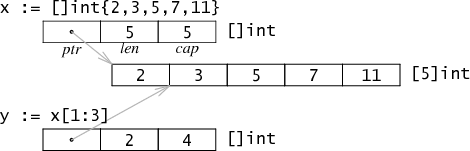
一个[slice](http://golang.org/doc/effective_go.html#slices)是一个数组某个部分的引用。在内存中,它是一个3字长结构,包含一个指向第一个元素的指针,slice的长度`length`以及容量`capacity`。`length`是标引操作的上界,如`x[i]`,`capacity`是分割操作(slice)的上界,如`x[i:j]`。
如同分割一个字符串,分割数组也不涉及复制操作:它只是新建了一个结构来放置一个不同的指针,长度和容量。在例子中,对`[]int{2,3,5,7,11}`求值操作会创建一个包含五个值的数组,并设置x的属性来描述这个数组。分割表达式`x[1:3]`并不分配更多的数据:它只是写了一个新的slice结构的属性来引用相同的存储数据。在例子中,长度为2--只有`y[0]`和`y[1]`是有效的索引--但是容量为4--`y[0:4]`是一个有效的分割表达式。(更多关于长度和容量以及使用slice的内容,请见[Effective Go](http://golang.org/doc/effective_go.html#slices)。)
由于slice是不同于指针的多字长结构,分割操作并不需要分配内存,甚至没有通常被保存在堆栈中的slice头部。这种表示方法使slice操作和在C中传递显式指针、长度对一般廉价。Go语言最初使用一个指向以上结构的指针来表示slice,但是这样做意味着每个slice操作都会分配一块新的内存对象。即使使用了快速的分配器,还是给垃圾收集器制造了很多没有必要的工作。而且我们发现,在上述字符串的情况下,程序避免slice操作,有利于传递显示索引(explicit indices)。绝大部分情况下,移除间接引用及分配操作可以让slice足够廉价,以避免传递显式索引。 ### New 和 Make Go有两个数据结构创建函数:new和make。两者的区别在学习的初期是一个常见的混淆点,但这个问题很快就可以迎刃而解。基本的区别是`new(T)`返回一个`*T`,返回的这个指针可以被隐式地消除引用(图中的黑色箭头)。而`make(T,args)`返回一个普通的`T`。通常情况下,T内部有一些隐式的指针(图中的灰色箭头)。一句话,new返回一个指向已清零内存的指针,而make返回一个复杂的结构。
有一种方法可以统一这两种创建方式,但是可能会与C/C++的传统有显著不同:定义`make(*T)`来返回一个指向新分配的T的指针,这样一来,`new(Point)`得写成`make(*Point)`。我们这样做了几天就放弃了--实在是和人们期望的分配函数太不一样了。
(本文发表于2009.11.24,作者使用的Go语言实现可能与现在的有所不同)
