而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息。 如何查看统计信息
查看sql Server的统计信息非常简单,使用如下指令:
DBCC SHOW_STATISTICS('表名','索引名')所得到的结果如图1所示。
图1.统计信息
统计信息如何影响查询下面我们通过一个简单的例子来看统计信息是如何影响查询分析器。我建立一个测试表,有两个INT值的列,其中id为自增,ref上建立非聚集索引,插入100条数据,从1到100,再插入9900条等于100的数据。图1中的统计信息就是示例数据的统计信息。
此时,我where后使用ref值作为查询条件,但是给定不同的值,我们可以看出根据统计信息,查询分析器做出了不同的选择,如图2所示。
图2.根据不同的谓词,查询优化器做了不同的选择
其实,对于查询分析器来说,柱状图对于直接可以确定的谓词非常管用,这些谓词比如:
where date = getdate()
where id= 12345
where monthly_sales < 10000 / 12
where name like “Careyson” + “%”
但是对于比如
where price = @vari
where total_sales > (select sum(qty) from sales)
where a.id =b.ref_id
where col1 =1 and col2=2
这类在运行时才能知道值的查询,采样步长就明显不是那么好用了。另外,上面第四行如果谓词是两个查询条件,使用采样步长也并不好用。因为无论索引有多少列,采样步长仅仅存储索引的第一列。当柱状图不再好用时,sql Server使用密度来确定最佳的查询路线。
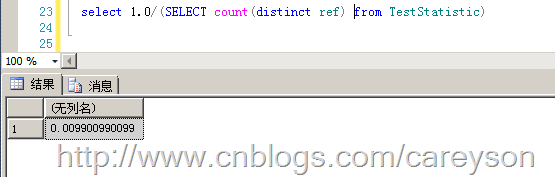
密度的公式是:1/表中唯一值的 个数。当密度越小时,索引越容易被选中。比如图1中的第二个表,我们可以通过如下公式来计算一下密度:
图3.某一列的密度
根据公式可以推断,当表中的数据量逐渐增大时,密度会越来越小。
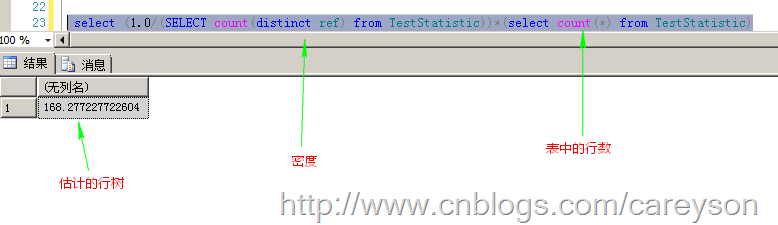
对于那些不能根据采样步长做出选择的查询,查询分析器使用密度来估计行数,这个公式为:估计的行数=表中的行数*密度
那么,根据这个公式,如果我做查询时,估计的行数就会为如图4所示的数字。
图4.估计的行数
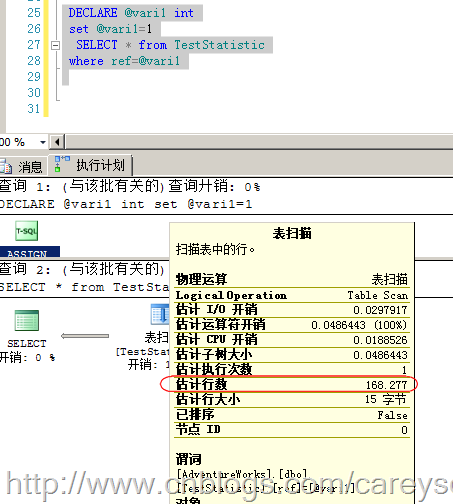
我们来验证一下这个结论,如图5所示。
图5.估计的行数
因此,可以看出,估计的行数是和实际的行数有出入的,当数据分布均匀时,或者数据量大时,这个误差将会变的非常小。
统计信息的更新由上面的例子可以看到,查询分析器由于依赖于统计信息进行查询,那么过时的统计信息则可能导致低效率的查询。统计信息既可以由sql Server来进行管理,也可以手动进行更新,也可以由sql Server管理更新时手动更新。
当开启了自动更新后,sql Server监控表中的数据更改,当达到临界值时则会自动更新数据。这个标准是:
向空表插入数据时 少于500行的表增加500行或者更多 当表中行多于500行时,数据的变化量大于20%时上述条件的满足均会导致统计被更新。
当然,我们也可以使用如下语句手动更新统计信息。
UPDATE STATISTICS 表名[索引名]
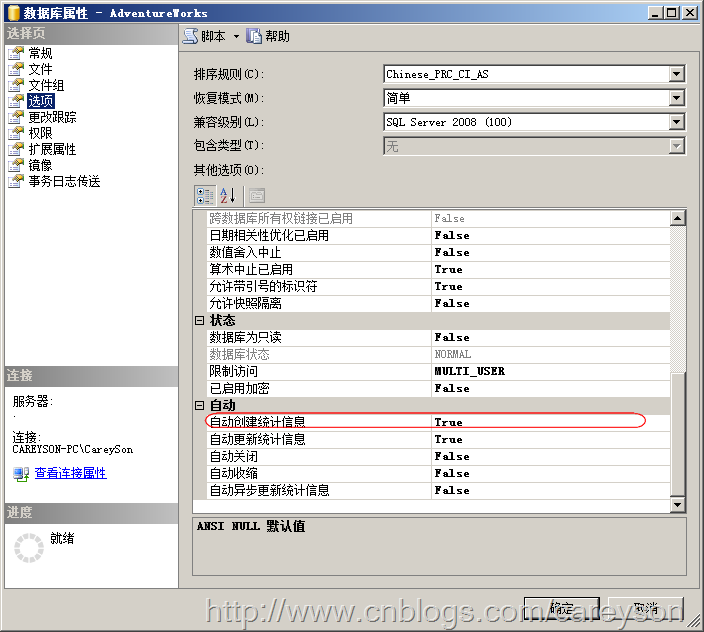
列级统计信息sql Server还可以针对不属于任何索引的列创建统计信息来帮助查询分析器获取”估计的行数“.当我们开启数据库级别的选项“自动创建统计信息”如图6所示。
当这个选项设置为True时,当我们where谓词指定了不在任何索引上的列时,列的统计信息会被创建,但是会有以下两种情况例外:
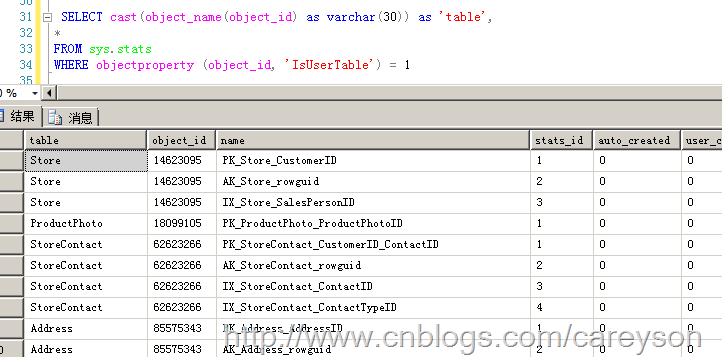
创建统计信息的成本超过生成查询计划的成本 当sql Server忙时不会自动生成统计信息我们可以通过系统视图sys.stats来查看这些统计信息,如图7所示。
图7.通过系统视图查看统计信息
当然,也可以通过如下语句手动创建统计信息:
CREATE STATISTICS 统计名称 ON 表名 (列名 [,...n])
总结
本文简单谈了统计信息对于查询路径选择的影响。过时的统计信息很容易造成查询性能的降低。因此,定期更新统计信息是DBA重要的工作之一。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}