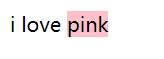正则表达式都是操作字符串的
作用:对数据进行查找、替换、有效性验证
创建正则表达式的两种方式:
// 字面量方式 /js/ 构造函数方式 regular expression new RegExp()
普通字符:字母 数字 汉字 _ 空格 ;,@ (没有特殊含义的符号)
两种匹配的方式:
test 测试,找到返回true,反之为false
exec 匹配字符,找到的话就返回该字符(以数组形式),反之返回null
这两个都是属于正则的方法,所以前面是跟的正则
var str="i love js"; var pattern=/js/; console.log(pattern.test(str));true console.log(pattern.exec(str));["js",index: 7,input: "i love js",groups: undefined] var pattern=/Js/false console.log(pattern.exec(str));null
正则默认情况下是区分大小写的
使用模式修饰符可以设置不区分大小写
三种模式修饰符:
i ignoreCase 忽略大小写
g global 全局匹配
m multiline 多行匹配
; i; console.log(pattern.test(str));var pattern=new RegExp("js"); console.log(pattern.test(str));new RegExp("Js"null new RegExp("Js","i"函数方式的区别:/js/i 直观简洁
new RegExp("js","i") 可以由于变量的检测
var userInput="js";需要匹配的字符在变量中 var pattern=/userInput/i;该方式不可取,直接匹配的是userInput console.log(pattern.test(str));var pattern="/"+userInput+"/i";该方式不可取,正则变为了字符串,不再具有test和exec方法 console.log(typeof pattern);string console.log(pattern.test(str));报错 console.log(pattern.exec(str));报错 new RegExp(userInput,1)">); console.log(object 正则属于正则对象 console.log(pattern.test(str));var str="//我是注释"; var pattern=/\/\//; console.log(pattern.exec(str)); ["//",index: 0,input: "//我是注释",groups: undefined]字符串中如果存在 \ ,默认会对下一个字符进行转义,如果需要作为普通字符处理,就对转义字符 \ 再进行转义处理 \\
var str="\\\\"; console.log(str); 结果只显示\\普通字符加上 \ 可能会有特殊含义
如 \n 代表换行
var str="nba"; var pattern=/n/; console.log(pattern.exec(str));匹配n ["n",input: "nba",groups: undefined] var pattern2=/\n/; console.log(pattern2.exec(str));匹配换行符 null\t 匹配 tab键
var str=" hello"var pattern=/\t/匹配n [" ",input: " hello",groups: undefined]可以用 ascii码 来正则匹配字符
var str="hello\ncyy"var pattern=/\x0A/匹配\n ["↵",index: 5,input: "hello↵cyy",groups: undefined]可以用 unicode 编码来正则匹配字符
var str=" 前面是tab键"var pattern=/\u0009/匹配tab键 [" ",input: " 前面是tab键",groups: undefined]unicode 常用于匹配汉字
匹配一个字符串中的所有中文:\u4e00-\u9fa5
var str="i am 陈莺莺"var pattern=/[\u4e00-\u9fa5]/匹配中文 ["陈",input: "i am 陈莺莺",groups: undefined]
可以匹配换行符的有: \n \x0A \u000A
字符类
[ ] 匹配中间的任意一个字符
var str="javascript"var pattern=/[js]/匹配j ["j",input: "javascript",groups: undefined][^ ] 表示取反
var pattern=/[^js]/;匹配除了j和s之外的 console.log(pattern.exec(str)); ["a",index: 1,groups: undefined][ ] 中间可以是一个范围
var pattern=/[k-z]/;匹配k-z之间的字母 console.log(pattern.exec(str)); ["v",index: 2,groups: undefined]表示范围时,前面的必须小于等于后面的
var pattern=/[c-c]/;前面等于后面 console.log(pattern.exec(str)); ["c",1)">var pattern2=/[c-b]/;前面大于后面 console.log(pattern2.exec(str)); 报错同时匹配大小写字母
var str="JavaScript"var pattern=/[a-zA-Z]/; ["J",input: "JavaScript",groups: undefined]匹配所有数字 0-9
var str="JavaScript3333"var pattern=/[0-9]/ ["3",index: 10,input: "JavaScript3333",groups: undefined][ ] 中间可任意组合,如
[a-zA-Z0-9@_]
常用的字符类:
. 匹配所有除了 \n 之外的字符
var str="3.14"var pattern=/./如果单纯匹配 . 转义即可
var pattern=/\./ [".",groups: undefined]. 不能匹配换行符
var str="\n" null数字字母下划线
/[a-zA-Z0-9_]/ = /\w/
/[^a-zA-Z0-9_]/ = /\W/
var str="@_"var pattern=/\w/ ["_",input: "@_",groups: undefined]数字
/[0-9]/ = /\d/
/[^0-9]/ = /\D/
var str="@_123"var pattern=/\d/ ["1",input: "@_123",groups: undefined]/ / 匹配空格
/ / 匹配 tab
/\s/ 匹配空格或者制表符(tab)
/\S/ 匹配除了空格或者制表符之外的其他字符
匹配的顺序取决于字符串中的顺序
var str=" 9"var pattern=/[\d\s]/ [" ",input: " 9",groups: undefined]重复
{n} 表示量词,出现 n 次
var str="123456789"var pattern=/\d{3}/;匹配3个数字 console.log(pattern.exec(str)); ["123",input: "123456789",groups: undefined]{n1,n2} 表示出现次数大于等于n1,小于等于n2
var pattern=/\d{2,3}/;匹配2-3个数字,会尽可能多的匹配 console.log(pattern.exec(str));错误的var pattern=/\d{1,}/ ["123456789",1)">var pattern2=/\d{,2}/;这种写法是错误的 console.log(pattern2.exec(str)); null? = {0,1} 匹配0次或者1次
var pattern=/\d?/var pattern=/\d+/包括0次)var pattern=/\d*/var str="肯德基豪华午餐¥15.5元"var pattern=/\d+\.?\d*/前面的数字 至少有1位 . 出现0次或者1次 后面的数字 可以有也可以没有,任意次 console.log(pattern.exec(str)); ["15.5",index: 8,input: "肯德基豪华午餐¥15.5元",groups: undefined]匹配正整数和负整数
var pattern=/-?[1-9]\d*/var pattern=/-{0,1}[1-9]\d*/;非贪婪的重复
正则匹配默认是贪婪模式,存在量词时会尽可能多的匹配
var str="aaab"var pattern=/a+/["aaa",input: "aaab",groups: undefined]在量词后面加上 ? ,表示由贪婪模式转为非贪婪模式,尽可能少的匹配
var pattern=/a+?/["a",groups: undefined]但是正则有一个原则,就是去找第一个可能匹配的字符
而不是最合适的位置
var pattern=/a+?b/;此处并不会匹配到ab console.log(pattern.exec(str));["aaab",groups: undefined]如上,并不会匹配到ab,因为正则从0开始就匹配到了a,之后会一直沿着下去寻找b
贪婪匹配与非贪婪匹配的应用
var str="<td>第一格</td><td>第二格</td>"var pattern=/<td>.*<\/td>/;贪婪模式,匹配两格 console.log(pattern.exec(str));["<td>第一格</td><td>第二格</td>",input: "<td>第一格</td><td>第二格</td>",1)">var pattern2=/<td>.*?<\/td>/;非贪婪模式,匹配一格 console.log(pattern2.exec(str));["<td>第一格</td>",groups: undefined]选择 |
var str="css js"var pattern=/js|html|css/["css",input: "css js",groups: undefined]选择最先匹配的,而不是最合适的
var str="ab"var pattern=/a|ab/;先尝试匹配a,匹配成功后,不再匹配ab console.log(pattern.exec(str));正则匹配上传图片的后缀名:一般图片的后缀名有gif,jpg,jpeg,png等,并且不区分大小写
/\.gif|\.jpg|\.jpeg|\.png/i
分组和引用 ()
var str="abab"var pattern=/(ab)+/;将ab看成一个整体 console.log(pattern.exec(str));(2) ["abab","ab",input: "abab",groups: undefined]返回的数组中,第一个元素是匹配到的结果,第二个元素是 () 中分组的元素
( ) 捕获分组
(?: ) 不捕获分组
var str="abcd"var pattern=/(abc)d/;匹配到abcd,捕获到abc console.log(pattern.exec(str));(2) ["abcd","abc",input: "abcd",groups: undefined] var pattern=/(?:abc)d/;匹配到abcd,没有捕获 console.log(pattern.exec(str));var pattern=/(ab)(cd)/;匹配到abcd,第一个分组ab,第二个分组cd console.log(pattern.exec(str));["abcd","cd",groups: undefined]嵌套分组,按左边括号的顺序来进行返回
var pattern=/(a(b(c(d))))/(5) ["abcd","abcd","bcd","d",groups: undefined]可以在正则中直接使用分组 \n 代表第n个分组
var str="abcdab"var pattern=/(ab)cd\1/;\1代表第一个分组,即ab console.log(pattern.exec(str));(2) ["abcdab",input: "abcdab",groups: undefined]分组的实际应用
匹配外层容器中的html文本,外层容器是不确定的标签
var str="<div><p>这是html文本</p></div>"var pattern=/<([a-zA-Z]+)>(.*?)<\/\1>/;\1代表闭合标签,必须与开始标签相同 console.log(pattern.exec(str));["<div><p>这是html文本</p></div>","div","<p>这是html文本</p>",input: "<div><p>这是html文本</p></div>",groups: undefined]如上,第一个分组是外层标签名,第二个分组是获取到的内层html
.exec 返回的数组:
匹配到的结果
分组依次返回
index 匹配到的位置索引
input 被匹配的字符串
位置匹配之首尾匹配
^ 字符串的开始
$ 字符串的结束
var str="js"var pattern=/^js/var str="html js"null匹配全是数字
var str="123mm567"var pattern=/^\d+$/null if(pattern.test(str)){ alert("全是数字"); }else{ alert("不全是数字");不全是数字 }反向思考,匹配不是数字
var pattern=/\D/["m",index: 3,input: "123mm567",1)">if(!pattern.test(str)){ alert("全是数字"不全是数字 }位置匹配之单词边界匹配
单词边界 \b
非单词边界 \B
var str="js html"var pattern=/js\b/var str="@@@js@@@";@也属于单词边界 var pattern=/\bjs\b/<!DOCTYPE html> <html lang="en"> <head> <Meta charset="UTF-8"> <title>Document</title> </head> <body> <ul> <li class="odd1 odd odd2">1</li> <li class="even">2</li> <li class="odd">3</li> <li class="even">4</li> </ul> <script> function getByClass(className,node){ 高版本浏览器 (document.getElementsByClassName(className)){ return document.getElementsByClassName(className) }{ IE低版本浏览器 var node=node || document; var arr=[]; var elements=node.getElementsByTagName("*");获取所有元素 注意,使用构造函数创建正则,其中的转义字符需要进行双重转义 new RegExp("(^|\\s+)"+className+"($|\\s+)"); for(var i=0;i<elements.length;i++){ 匹配className (pattern.test(elements[i].className)){ arr.push(elements[i]); } } arr; } } var odds=getByClass("odd"); var i=0;i<odds.length;i++){ odds[i].style.background="pink"; } var evens=getByClass("even"var i=0;i<evens.length;i++){ evens[i].style.background="#abcdef"; } </script> </body> </html>
使用单词边界的思路也可实现
<!DOCTYPE html> <html lang="en"> <head> <Meta charset="UTF-8"> <title>Document</title> </head> <body> <ul> <li class="odd1 odd odd2">1</li> <li class="even">2</li> <li class="odd">3</li> <li class="even">4</li> </ul> <script> new RegExp("\\b"+className+"\\b"; } </script> </body> </html>前瞻性匹配 (?= )
var pattern=/java(?=script)/;如果java后面跟的是script,那么匹配出java console.log(pattern.test(str));true var str="java"false负前瞻性匹配 (?!)
var pattern=/java(?!script)/;如果java后面跟的是script,那么不匹配出java console.log(pattern.test(str));false 如果java后面跟的不是script,那么匹配出java console.log(pattern.test(str));trueRegExp 对象的实例方法
其中的转义字符需要进行双重转义
new RegExp("\b"); console.log(pattern); // new RegExp("\\b" /\b/因此,如果是 \ ,直面量方式转义为 \\,构造函数双重转义为 \\\\
new RegExp("\\\\" /\\/pattern 就是正则实例的对象,pattern 拥有的方法就是实例方法
如: .test() .exec()
var str="js js js"; console.log(pattern.exec(str)); ["js",input: "js js js",groups: undefined] console.log(pattern.exec(str));g; console.log(pattern.exec(str)); null console.log(pattern.exec(str));属性,叫 lastIndex,默认是0如果设置为全局匹配,则 lastIndex 是上一次匹配的结束位置的下一位
如果匹配到为 null,就会自动重置为0,再次进行下一轮
分组之后也能捕获
var pattern=/(j)s/ (2) ["js","j",groups: undefined] console.log(pattern.exec(str));var str="1.js 2.js 3.js"g; var total=0;出现的总次数 var result; while((result=pattern.exec(str))!=null){先赋值再进行判断 total++; console.log(result[0]+"第"+total+"次出现的位置是:"+result.index); } console.log("总共出现了"+total+"次");test 与 exec 类似原理
true console.log(pattern.test(str));g; console.log(pattern.test(str));false console.log(pattern.test(str));true.toString() 转字符串
.toLocaleString() 转本地字符串(仅限少数语言)
.valueOf() 返回正则本身
new RegExp("a\\nb"); console.log(pattern.toString()); /a\nb/ 此处返回的是字面量形式的字符串 console.log(pattern.toLocaleString()); /a\nb/ console.log(pattern.valueOf()); /a\nb/ console.log(pattern.valueOf()===pattern); true实例属性
.ignoreCase 判断是否忽略大小写
.global 是否全局
.multiline 是否匹配到多行
.source 返回字面量正则本身
im; console.log(pattern.ignoreCase);true console.log(pattern.global);false console.log(pattern.multiline);true console.log(pattern.source);js console.log(pattern.source===pattern);false.lastIndex 最后一次匹配的位置的后一位
var str="js js"; console.log(pattern.lastIndex);0 pattern.test(str); console.log(pattern.lastIndex);0 g; console.log(pattern.lastIndex);2 5 0 匹配不到时重置到0 2.input 待匹配的字符串 = $_
.lastMatch 最近一次匹配到的字符 = $&
.leftContext 最近一次匹配时左边的字符 = $`
.rightContext 最近一次匹配时右边的字符 = $'
.lastParen 最近一次匹配到的子选项(分组中的内容) = $+
.$n 捕获分组
; pattern.exec(str); 待匹配的字符串 console.log(RegExp.input);js js console.log(RegExp["$_"]);js js 最近一次匹配到的字符 console.log(RegExp.lastMatch);js console.log(RegExp["$&"]);js 最近一次匹配时左边的字符 console.log(RegExp.leftContext);空 console.log(RegExp["$`"]);空 最近一次匹配时右边的字符 console.log(RegExp.rightContext); js console.log(RegExp["$'"]); js 最近一次匹配到的子选项(分组中的内容) console.log(RegExp.lastParen); j console.log(RegExp["$+"]); j 捕获分组 console.log(RegExp.$1); jstring 对象中,与正则相关的方法
str.search() 与是否全局无关,只查找一个,如果有,就返回 index
如果没有,就返回 -1
; console.log(str.search(pattern));var pattern=/aa/-1str.match()
普通匹配时与 exec 相同
全局匹配时:直接返回所有匹配的元素,分组会失效
; console.log(str.match(pattern));(2) ["js",input: "js js",groups: undefined] g; console.log(str.match(pattern)); nullstr.match( pattern )
非全局匹配时才能返回分组中的内容
全局匹配时会返回所有匹配到的字符
m 和 g 组合,结合首尾匹配,体现
var str="1.js\n2.js\n3.js"var pattern=/js$/g;匹配行尾的js,默认是一行 console.log(str.match(pattern));["js"] var pattern=/js$/mg;匹配行尾的js,默认是多行 console.log(str.match(pattern));(3) ["js","js","js"]str.split() 字符串分割,转为数组
var str="1,2,3"; console.log(str.split(","));(3) ["1","2","3"] var pattern=/\s*,\s*/g; console.log(str.split(pattern));str.replace()
var str="i love js js"; console.log(str.replace("js","html"));i love html js g; console.log(str.replace(pattern,"html"));i love html htmlreplace 替换时间格式
var str="2020-2-15"var pattern=/-/2020/2/15使用 $n 进行分组引用
var str="i love pink"var pattern=/(pink)/g; document.write(str.replace(pattern,"<span style='background:pink'>$1</span>"));
敏感词的过滤
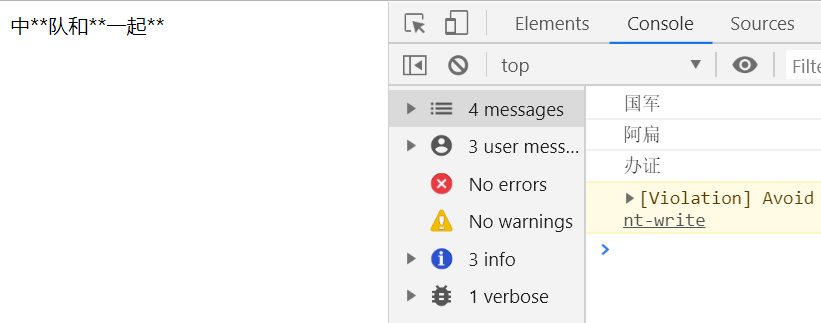
var str="中国军队和阿扁一起办证"var pattern=/国军|阿扁|办证/中*队和*一起*一个文字对应一个 * 号
$0 是每次匹配到的内容
function($0){ console.log($0var result=""var i=0;i<$0.length;i++){ result+="*" result; }));中**队和**一起**
f5 浅刷新
ctrl+f5 深度刷新
常用的正则表达式:
1、QQ号:
全数字 首位不是0 最少5位 (目前最多11位,以后可能会扩增)
/^[1-9]\d{4,10}$/ /^[1-9]\d{4,}$/2、用户名、昵称
2-18位 中英文数字及下划线组成
/^[\ue400-\u9fa5\w]{2,18}$/ /^[\ue400-\u9fa5a-zA-Z0-9_]{2,18}$/3、密码
6-16位 不能有空白符 区分大小写
/^\S{6,16}$/4、去除字符串首尾的空白字符
首先是去除首部或者尾部
var str=" cyy "; console.log("|"+str+"|"); | cyy | var pattern=/^\s+/; str=str.replace(pattern,"");替换左边空白符 var pattern2=/\s+$//* 这里使用 \s+ 比使用 \s* 效率高 \s* 无论如何都会进行替换,哪怕没有空白符 \s+ 只在有空白符的时候进行替换,否则直接返回 */ str=str.replace(pattern2,1)">替换右边空白符 console.log("|"+str+"|"); |cyy|同时去除首尾空白符
var pattern=/^\s+|\s+$/g; str=str.replace(pattern,1)">替换左右空白符 console.log("|"+str+"|"); |cyy|trim(str){ return str.replace(/^\s+/,"").replace(/\s+$/,""); } console.log("|"+trim(str)+"|"); |cyy|5、转驼峰
str.replace(pattern,要替换的内容) 第二个参数可以是一个匿名函数的返回值
匿名函数的参数中,第一个参数是匹配的内容,第二个参数开始是分组捕获的内容
var str="background-color"var pattern=/-([a-z])/gi; 此处匹配到-c 因为在匹配的结果中,第一个参数是匹配的内容,第二个参数开始是分组的内容 //因此此处all为 -c letter为 c也可以用$0 $1表示 console.log(str.replace(pattern,(all,letter){ letter.toUpperCase(); })); backgroundColor console.log(str.replace(pattern,1)">function($0,$1){ return $1.toUpperCase(); })); backgroundColor 封装转驼峰函数 toCamelCase(str){ return str.replace(pattern,1)">){ .toUpperCase(); }); } console.log(toCamelCase(str));backgroundColor6、匹配HTML标签
var str="<p style='color:red' class='active'>这是段落</p>"var pattern=/<.+?>/g;非贪婪模式匹配两个尖括号之间的内容 console.log(str.match(pattern)); var pattern=/<[^>]+>/g;两个尖括号内部,没有匹配到结束的尖括号 console.log(str.match(pattern));7、email 邮箱
cyy@qq.com.cn
cyy_1@qq.com
cyy.com@qq.com.cn
/^(\w+\.)*\w+@(\w+\.)+[a-z]$/i8、URL
http://www.baicu.com http或者https 可有可无 除了 : 和 / ,其他的都属于主机名 */ 简化版,要求不高 /^(https?:\/\/)?[^:\/]+(:\d+)?(\/.*)?$/ 精确版协议: http:// https:// ftp:// mailto:// file:/// 匹配主机名 www.baidu.com可以有连字符,但是连字符不能作为开头和结尾 /^([a-z0-9]+\.|[a-z0-9]+-[a-z0-9]+\.)*[a-z]+$/i可以把经常用的正则存到一个对象中,如:
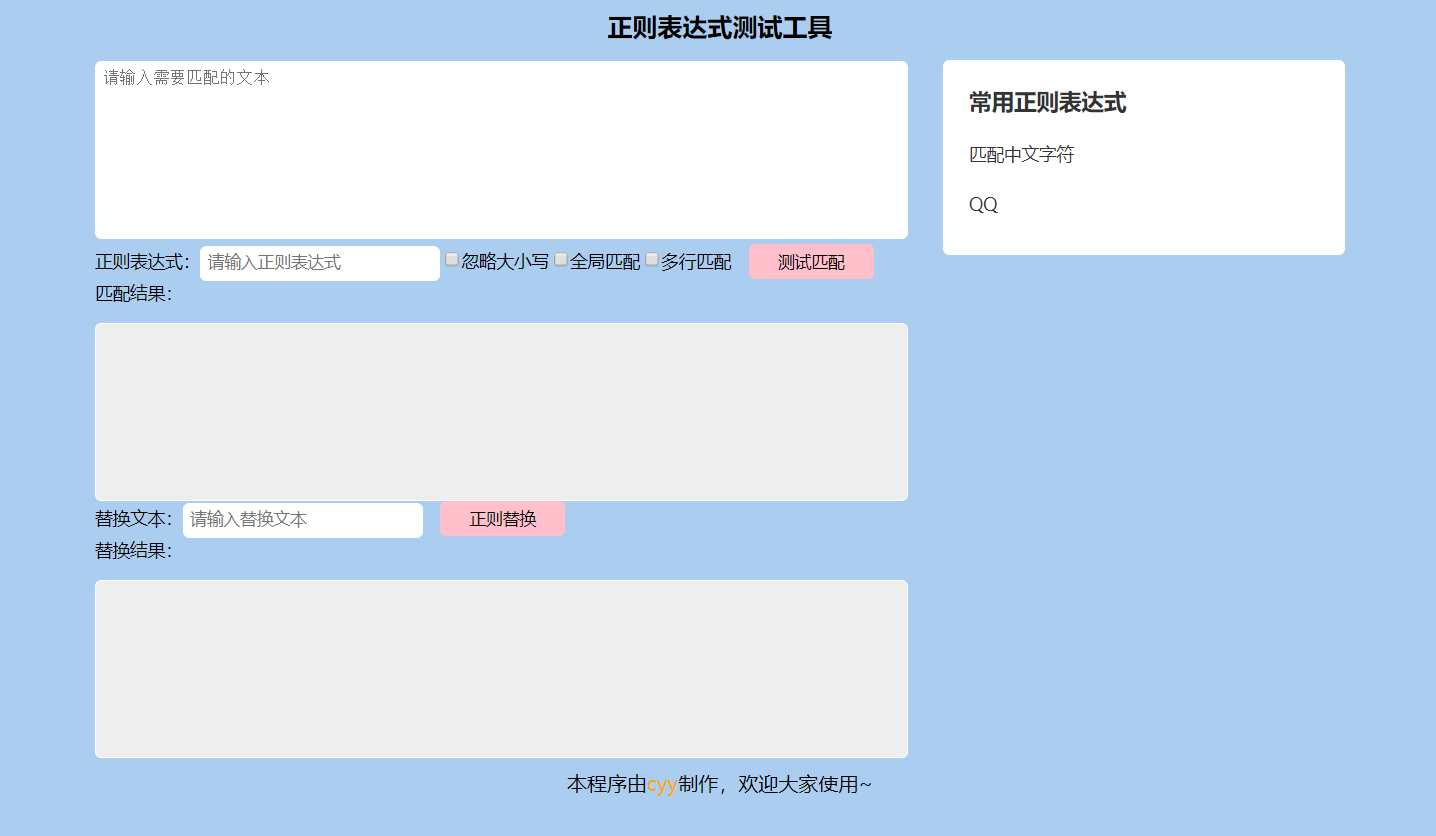
var regExp={ "chinese":/[\u4e00-\u9fa5]/,"qq":/^[1-9]\d{4,}$/<!DOCTYPE html> <html lang="en"head> Meta charset="UTF-8"name="viewport" content="width=device-width,initial-scale=1.0"title>Document</style> *{ margin:0; padding; } body background#abcdef .wrap width1000px margin10px auto font-size14px .container650px floatleft .wrap h1 text-align center20px .textBox border1px solid #fff5px638px height130px border-radius resizenone/*不允许拖拽输入框*/ margin-top15px div.textBox#eee .pattenInput180px .matchBtn100px background-color pink margin-left10px #matchResult span,#replaceResult spanorange .list280pxright #fff .list dt font-weightbold18px margin-bottom color#333 .list dd40px line-height .list dd a display block text-decoration none .list dd a:hover .footer zoom1 .wrap::after content"" clearboth .footer span} bodydiv class="wrap"> h1>正则表达式测试工具="container"> textarea id="userInput" class="textBox" placeholder="请输入需要匹配的文本"></textareap> 正则表达式:input type="text"="请输入正则表达式"="pattenInput" id="pattenInput"> ="checkBox" name="modifier" value="i"忽略大小写 ="g"全局匹配 ="m"多行匹配 ="button"="测试匹配"="matchBtn"="matchBtn" 匹配结果: <!-- 原来使用textarea,内部文本不允许加标签,因此换为div --> ="matchResult"div 替换文本:="请输入替换文本"="replaceInput"="正则替换"="replaceBtn" 替换结果: ="replaceResult"dl ="list"="list"dt>常用正则表达式dd><a href="javascript:void(0)" title="[\u4e00-\u9fa5]">匹配中文字符a="[1-9]\d{4,}">QQdlp ="footer">本程序由span>cyy>制作,欢迎大家使用~> script> var userInput=document.getElementById("userInput); pattenInputpattenInput modifiersdocument.getElementsByName(modifier matchBtnmatchBtn matchResultmatchResult); replaceInputreplaceInput replaceBtnreplaceBtn replaceResultreplaceResult linkslist).getElementsByTagName(a pattern; modifier; //处理模式修饰符 for( i;i<modifiers.length;i++){ modifiers[i].onclickfunction(){ modifier每次点击后先清空原来的 j;jmodifiers.length;j){ if(modifiers[j].checked){ modifier+=modifiers[j].value; } } } } 点击按钮进行匹配 matchBtn.onclick(){ 没有输入文本 !userInput.value){ alert(请输入待匹配的文本~); userInput.focus();获取光标 return不再执行下面的脚本 } 没有输入正则 pattenInput.value){ alert(); pattenInput.focus(); ; } patternnew RegExp(+pattenInput.value)pattern.exec(userInput.value) ? userInput.value.replace(pattern,<span>$1</span>): (没有匹配到哦~); } 点击按钮进行替换 replaceBtn.onclick; } 没有输入替换文本 replaceInput.value){ alert(请输入要替换的文本~); replaceInput.focus(); userInput.value.replace(pattern,1)"><span>replaceInput.value</span>); } 点击右侧快捷正则 links.length;i){ links[i].onclick(){ pattenInput.valuethis.title;this指当前点击的元素 } } html>
补充:
() 分组可以捕获内容
(?:) 不参与捕获
$1 $2... 分别表示捕获到的内容
exec() 返回的数组中,第一个是匹配到的内容,第二个开始是捕获的内容
/\1/ 模式中,直接在正则中引用捕获到的内容
replace() 的第2个参数中,$1 (如果第2个参数是匿名函数,这个匿名函数的第一个参数是匹配到的内容,第二个参数开始是捕获到的内容)
RegExp.$1